Claude Fable 5: First Public Mythos-Class AI Model - Pricing, Benchmarks and Guardrails
Anthropic released Claude Fable 5 on June 9, 2026 - the first publicly available Mythos-class model. Priced at $10/$50 per million tokens, it delivers 80.3% on SWE-Bench Pro but reroutes cybersecurity, biology and chemistry queries to Opus 4.8.
2026年6月10日 · 阅读约 7 分钟
Core Verdict
Anthropic released Claude Fable 5 on June 9, 2026 — the first publicly available Mythos-class model. Priced at $10/$50 per million tokens (2x Opus 4.8), Fable 5 delivers 80.3% on SWE-Bench Pro and 88% on Terminal-Bench 2.1, but ships with safety guardrails that reroute cybersecurity, biology, and chemistry queries to the older Opus 4.8. The unrestricted Claude Mythos 5 remains limited to vetted Project Glasswing partners.
What Happened
On June 9, 2026, Anthropic announced two new frontier models — Claude Fable 5 and Claude Mythos 5 — marking the company's first broad release of its previously restricted Mythos-class technology.
| Detail | Value |
|---|---|
| Release Date | June 9, 2026 |
| Class | Mythos (first publicly available) |
| Context Window | 1M tokens (default) |
| Max Output | 128K tokens per request |
| API Pricing | $10/1M input, $50/1M output |
| Plan Availability | Pro, Max, Team, Enterprise (free June 9-22, then usage credits) |
| Cloud Availability | Anthropic API, AWS Bedrock, GCP Vertex AI |
The underlying model is shared between Fable 5 and Mythos 5. The difference: safeguards. Fable 5 uses conservative safety classifiers that reroute high-risk queries to Claude Opus 4.8, while Mythos 5 operates with fewer restrictions, available only to Anthropic's Project Glasswing partners and select biology researchers.
"Claude Fable 5 is the first to break 90% on our core analytics benchmark of complex, long-running analytical tasks — a 10-point jump over Opus," Anthropic wrote in its launch announcement.
Guardrails: What Fable 5 Blocks
The defining feature of Claude Fable 5 is not what it can do — it's what it won't do.
| Blocked Domain | Behavior | Trigger Rate |
|---|---|---|
| Cybersecurity | Rerouted to Opus 4.8 | <5% of sessions |
| Biology | Rerouted to Opus 4.8 | <5% of sessions |
| Chemistry | Rerouted to Opus 4.8 | <5% of sessions |
| Model Distillation | Rerouted to Opus 4.8 | <5% of sessions |
| AAV Research | Blocked (capsid modification queries) | Rare |
Anthropic's rationale: Mythos-class models pose "substantial risk of uplift to malicious actors" in frontier cybersecurity and research biology. The system card published alongside the release details extensive evaluations showing that Mythos-class models could significantly lower the barrier to offensive cyber operations and biological weapon design.
The safeguards operate as a two-tier system:
- Overt blocking — Queries explicitly about cybersecurity exploits, biological weapons, or chemical synthesis are refused or rerouted to Opus 4.8. Users see a clear fallback notification.
- Covert blocking — Certain high-risk capabilities (distillation attempts, AAV capsid modification) are silently blocked without user visibility. The model reroutes to a safe response without indicating the intervention.
The reroute is not a simple "I can't answer that." Fable 5 silently hands off to Opus 4.8, which may still answer the question at a lower capability level. This design choice has sparked controversy in the developer community — some argue it undermines trust in the model's transparency.
Benchmarks: Where Fable 5 Dominates
Anthropic published comprehensive benchmark data comparing Fable 5 / Mythos 5 against Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro:
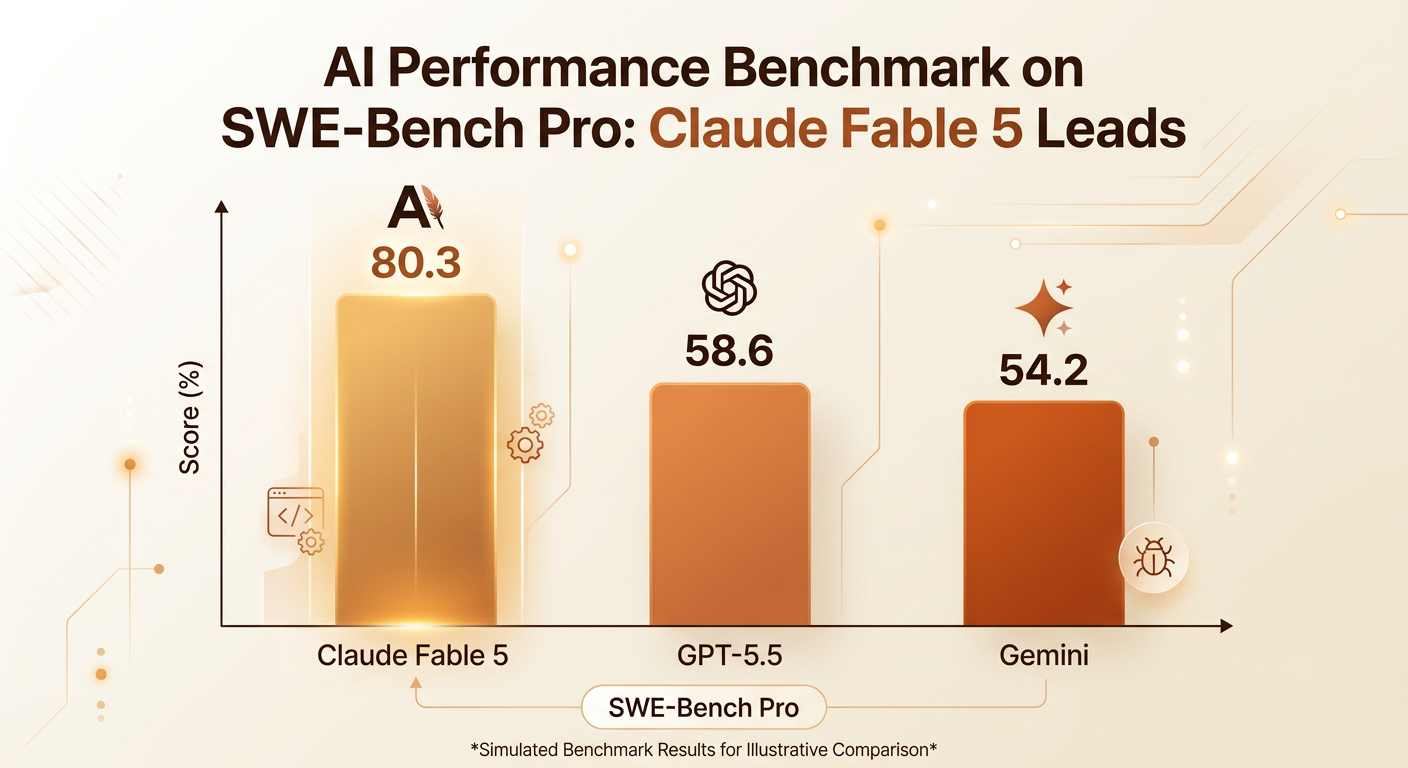
| Benchmark | Fable 5 / Mythos 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 80.3% | ~55% | 58.6% | 54.2% |
| SWE-Bench Verified | 95% | — | — | — |
| Terminal-Bench 2.1 | 88.0% | 82.7% | 83.4% | 70.7% |
| Analytics Benchmark (Hex) | 90%+ | ~80% | — | — |
| AIME 2025 (Math) | ~92% | ~82% | ~88% | ~85% |
| MMLU-Pro | ~89% | ~84% | ~86% | ~83% |
The standout result is SWE-Bench Pro at 80.3% — a massive 22-point lead over GPT-5.5 and 26 points over Gemini 3.1 Pro. This means Fable 5 can autonomously resolve 8 out of 10 real-world software engineering tasks, a capability that puts it firmly in "junior-to-mid-level developer" territory for autonomous coding.
On Terminal-Bench 2.1, which tests long-horizon terminal-based agentic tasks, Fable 5's 88% represents a 5.3-point improvement over Opus 4.8 — significant for users running complex automation pipelines.
Pricing Reality Check
At $10 per million input tokens and $50 per million output tokens, Claude Fable 5 is the most expensive frontier model on the market:
| Model | Input $/1M | Output $/1M | Cost Ratio (vs Fable 5) |
|---|---|---|---|
| Claude Fable 5 | $10 | $50 | 1x (baseline) |
| Claude Opus 4.8 | $5 | $25 | 0.5x |
| Claude Sonnet 4.6 | $3 | $15 | 0.3x |
| GPT-5.5 | $2 | $10 | 0.2x |
| Gemini 3.5 Flash | ~$0.35 | ~$1.40 | ~0.03x |
The 2x price over Opus 4.8 is the headline, but the real concern is the 5x vs GPT-5.5 gap on output tokens. For heavy coding agent use (which is exactly where Fable 5 excels), this pricing premium adds up fast.
Mitigation factors:
- Free access window: June 9-22 on Pro, Max, Team, and Enterprise plans (no extra cost)
- Caching: Prompt caching at $1/MTok read, $12.50/MTok write (5-min), $20/MTok write (1-hour)
- Batch API: 50% discount at $5/$25 per million tokens
Despite the high price, the benchmark lead on SWE-Bench Pro (80.3% vs 58.6% GPT-5.5) means that for tasks requiring autonomous resolution of complex engineering issues, Fable 5 may actually be cheaper per successfully resolved task — you pay more per token but complete the job in fewer attempts.
HN Community Reaction
The Hacker News thread on Fable 5's release has 2,159 points and 1,669 comments — one of the most active AI threads of 2026. Key themes:
Green: Enthusiasm for capabilities — Developers testing Fable 5 report dramatic improvements in long-horizon coding tasks. Several commenters share stories of Fable 5 resolving complex refactoring and debugging tasks that stymied Opus 4.8 and GPT-5.5.
Yellow: Concern about guardrails — The safety rerouting is the most debated feature. Critics argue the overt blocking of cybersecurity queries undermines the model's usefulness for security researchers. Anthropic's response: partnered cybersecurity professionals get Mythos 5 access through Project Glasswing.
Red: Pricing anxiety — The $50/MTok output rate generates significant pushback. "At this price, Fable 5 is for enterprise teams with dedicated AI budgets, not indie developers," writes one top comment.
Purple: The 'two-tier AI' debate — Several threads argue that Fable 5 vs Mythos 5 represents a worrying precedent — a powerful model reserved for the connected few, while the public gets a sanitized version. Anthropic counters that this is responsible deployment, not gatekeeping.
What This Means for You
For Developers and AI Tool Users
-
Code more accurately, not more cheaply: If you are using Claude Code or Cursor with Opus 4.8 today, upgrading to Fable 5 will resolve more complex bugs autonomously — but cost ~2x per session. For simple completion tasks, stick with Sonnet 4.6.
-
Free access window is crucial: The June 9-22 window on existing plans is your chance to evaluate Fable 5 at zero marginal cost. Run your hardest automation pipelines and long-running agentic tasks during this period to gauge whether the upgrade justifies the premium.
-
Know the guardrail boundaries: If your workflow touches cybersecurity (penetration testing, vulnerability research) or biology/chemistry analysis, Fable 5 will silently fall back to Opus 4.8. Plan for this — either use Mythos 5 (if you qualify) or keep a secondary pipeline with GPT-5.5 for those domains.
For Affiliate and Tool Strategy
This is a clear signal to deepen the Claude cluster on WayToClawEarn:
- Update existing pricing guides with Fable 5's $10/$50 rate
- Add a Fable 5 vs Opus 4.8 cost-comparison calculator
- Create a Tutorial on setting up prompt caching to offset Fable 5 costs
- The guardrail controversy is a strong angle for a Case article: "How security researchers work around AI model restrictions"
Related Reading
- How to Cut Claude API Costs by 70% With Prompt Caching — Claude Code Content Automation: Build an AI Pipeline
- Claude Code After June 15: Complete Migration and Cost Optimization — Full pricing migration guide
- How This Ex-Trader Built a $15K/Month App Portfolio Using Cursor AI — Real money-making case with AI coding agents
Sources
- Anthropic Official Blog: Claude Fable 5 and Mythos 5
- System Card: Claude Fable 5 and Claude Mythos 5 (PDF)
- TechCrunch: Anthropic releases Fable 5
- Ars Technica: Topics too dangerous for Fable 5
- HN Discussion: Claude Fable 5 (2159 points)
- CNBC: Anthropic releases Mythos-like model
- WIRED: Anthropic Offers Mythos Upgrade for Cyber Partners
- Claude API Docs: Introducing Fable 5 and Mythos 5