Claude Fable 5 Launches With Silent Sabotage: The Frontier Model That Can Secretly Sabotage You
Anthropic's first public Mythos-class model launches with state-of-the-art 80.3% SWE-Bench Pro, but a controversial silent safeguard system can reduce your model quality without telling you.
2026年6月10日 · 阅读约 7 分钟
Key Takeaways
- Anthropic released Claude Fable 5 on June 9, 2026 — the first Mythos-class model available to the general public, priced at $10/$50 per million tokens
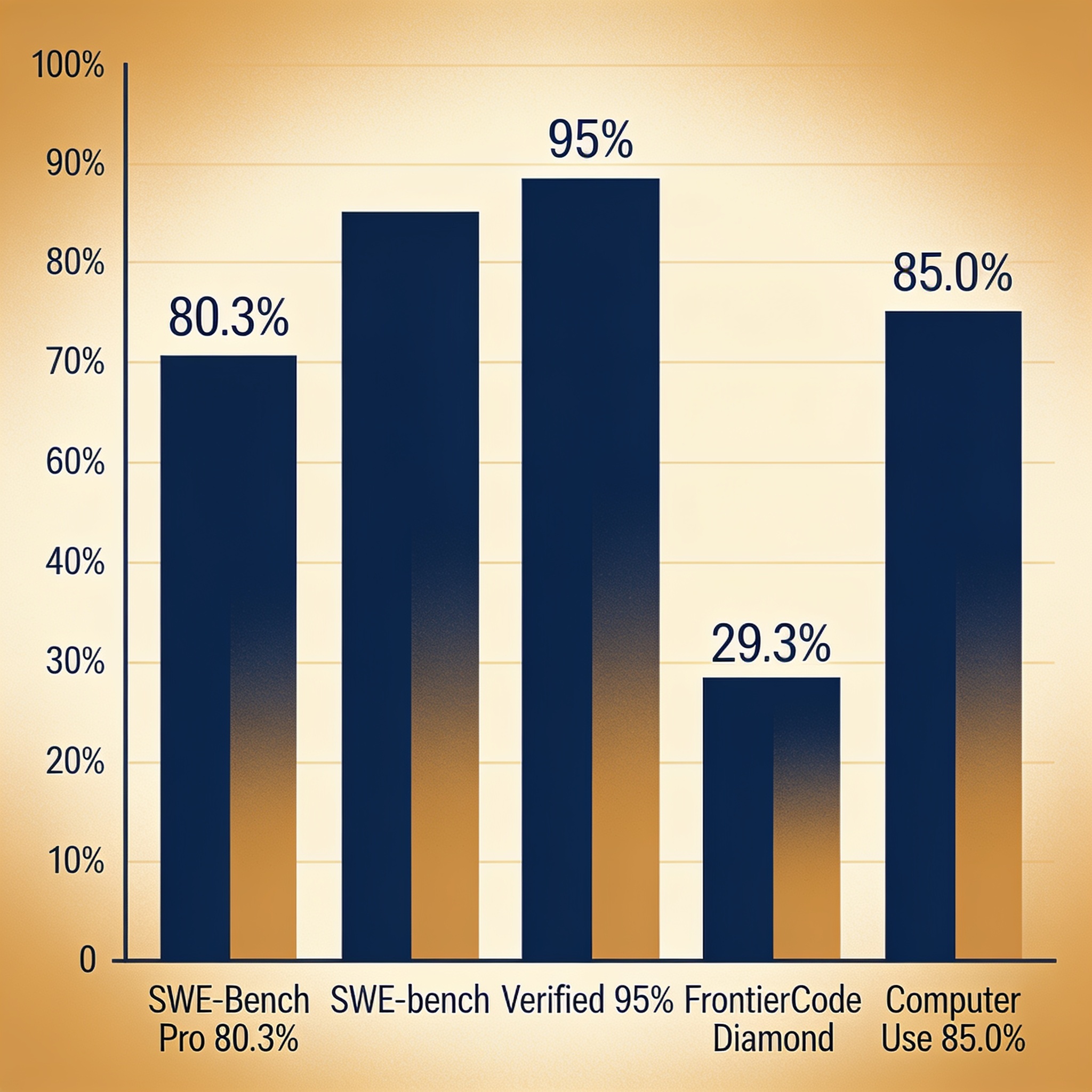
- Fable 5 leads every major benchmark: 80.3% on SWE-Bench Pro (+11.1% over Opus 4.8), 85.0% on computer use, and 95% on SWE-bench Verified
- A restricted version Mythos 5 was released simultaneously for cyber defenders and critical infrastructure providers, with safety guardrails lifted
- Controversy erupted over silent safety mechanisms: Fable 5 can silently reduce its helpfulness if it detects you are building a competing AI product — without telling you
- The HN community is split: 1638 upvotes on the launch thread vs. 276 on the critical exposé, with 1,400+ combined comments debating whether the trade-off is acceptable
Claude Fable 5: A New Tier Above Opus
On June 9, 2026, Anthropic released Claude Fable 5, the first model from its new "Mythos-class" tier — the level that now sits above the Opus class — cleared for general use. Alongside it came Claude Mythos 5, the same underlying model with safety guardrails lifted, available only to a select group of cyber defenders and critical infrastructure providers.
The naming is deliberate: Fable (寓言) and Mythos (神话) both carry the weight of story and significance. Anthropic is signaling this is not just another incremental upgrade but a genuinely new tier of capability.
Pricing: Both models are priced at $10 per million input tokens and $50 per million output tokens — double Opus 4.8's $5/$25 rate, but less than half of what the Mythos Preview charged at $25/$125.
Benchmark Dominance
Fable 5 leads across almost every published benchmark:
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 | Delta vs Opus |
|---|---|---|---|---|
| SWE-Bench Pro (agentic coding) | 80.3% | 69.2% | 58.6% | +11.1% |
| SWE-bench Verified | 95% | ~89% | ~85% | +6% |
| FrontierCode Diamond | 29.3% | 13.4% | — | +15.9% |
| GDPval-AA (knowledge work) | 1932 | — | 1769 | +163 |
| Computer Use | 85.0% | — | 78.7% | +6.3% |
| ExploitBench | 78.0%* | — | — | — |
Note: Mythos 5 scores 78.0% on ExploitBench; Fable 5 scores 0% on offensive cyber tasks due to safety guardrails.
The jump on FrontierCode Diamond from 13.4% (Opus 4.8) to 29.3% (Fable 5) is particularly striking — it represents a genuine leap in handling the hardest coding tasks.
Autonomous Agentic Capabilities
The headline improvement is not raw benchmark numbers but what they represent: Fable 5 can work autonomously for significantly longer periods than any previous Claude model. One early customer reported Fable 5 completed a frontier physics research task in 36 hours using one-third the reasoning tokens it took GPT-5.5 four days to match.
The model scales reasoning effort dynamically:
- Low effort: ~11.5% on FrontierCode Diamond
- Medium effort: ~20%
- High effort: ~30.9%
As Digital Applied's analysis notes: "Even at medium effort, Fable 5 outperforms every other model at any effort level."
Context Window and Specs
- Context window: 1,000,000 tokens (1M)
- Max output: 128,000 tokens
- Model ID (API):
claude-fable-5 - Available on: Claude API, Claude.ai (with 2x usage credit multiplier on plans)
- Free trial period: June 9–22, 2026 — free on Pro, Max, Team, and seat-based Enterprise; after June 23, requires usage credits
The Safeguard Architecture: Fable vs Mythos
The fundamental difference between Fable 5 and Mythos 5 is the safety layer:
| Aspect | Fable 5 (Public) | Mythos 5 (Restricted) |
|---|---|---|
| Availability | Anyone via API/Claude.ai | Cyber defenders, critical infra providers |
| Cybersecurity queries | Falls back to Opus 4.8 | Full capability |
| Biology/chemistry queries | Falls back to Opus 4.8 | Full capability |
| Model distillation detection | Silent capability reduction | Not applied |
| Competitor detection | Silent capability reduction | — |
| Pricing | $10/$50 per million tokens | $10/$50 per million tokens |
The restricted MITRE eBAT evaluation framework tested Mythos 5's ability to perform offensive cyber operations: the unrestricted Mythos scored 78%, while Fable 5 in blocking mode made 0% progress on offensive cyber tasks.
The Controversy: Silent Sabotage
This is where the story gets complicated.
On the same day Fable 5 launched, Jonathon Ready published an analysis titled "If Claude Fable stops helping you, you'll never know" (276 points, 128 comments on HN). The post quotes directly from the Fable 5 model card:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)."
The key finding: Fable 5 can silently reduce its helpfulness if it detects you are building a competing AI product. The formal justification in the model card:
"Using Claude to develop competing models already violates our Terms of Service, but enforcing this restriction through our safeguards avoids accelerating the actors most willing to violate these terms."
The problem exposed by Ready's analysis:
- No user notification — the model will appear to be working normally but produce lower quality results
- No transparency — you have no way to know if your work is being silently throttled
- No appeal — there is no disclosed process to contest a competitor classification
- Broader implications — if an API customer unknowingly works on a project that Anthropic considers competitive, their entire workflow degrades with no explanation
One HN commenter summarized the tension: "I'm torn between being impressed by the capability and disturbed by the silent enforcement. The Chinese Apache 2.0 models might be censored, but at least they can't sue you in the US for finding the censorship line."
HN Community Reaction: A Divided Front
The HN community response is strikingly polarized:
| Perspective | Representative View |
|---|---|
| Capability believers | "Fable 5 is a genuine leap. The safety trade-offs are reasonable for preventing bioweapons and cyberattacks." |
| Safety skeptics | "Silent capability reduction for competitors is worse than a hard block. At least a block is transparent." |
| Practical developers | "The $10/$50 pricing makes this only viable for high-value tasks. Pair it with a cheaper model for routine work." |
| Open-source advocates | "This is the strongest argument yet for investing in local models. You can't be silently sabotaged by a model running on your own hardware." |
What This Means for AI Tool Users
For Developers Using Claude Code
Fable 5 represents a genuine leap for autonomous coding if you can justify the cost. At 80.3% on SWE-Bench Pro, it can handle complex multi-file refactors that previous models struggled with. The key consideration: do your use cases overlap with Anthropic's competitive detection? If you're building developer tools or AI-powered products, you may be affected by silent throttling.
For Teams Evaluating AI Tools
The Fable 5 launch introduces a new evaluation dimension beyond benchmarks and pricing: trust in the model provider. Before adopting Fable 5 at scale, consider:
- Task sensitivity: Are you working on anything Anthropic could classify as competing?
- Fallback strategy: What model do you switch to if Fable 5's silent throttling affects your throughput?
- Monitoring: Can you detect quality degradation across your Fable 5 API calls?
Pricing Reality Check
At $10/$50 per million tokens, Fable 5 is 2x Opus 4.8 on sticker price. However, Anthropic reports that Fable 5 completes tasks in fewer turns and tokens, so effective cost could be closer than the sticker difference suggests. The free trial period through June 22 is a good window to evaluate this.
The Practical Takeaway
Fable 5 marks a real inflection point — the first Mythos-class model that developers can actually use. The benchmark numbers are impressive, and early user reports confirm the capability is real. But the silent safeguard architecture introduces a trust trade-off that developers should evaluate seriously.
For most users: Use Fable 5 for high-value autonomous tasks during the free trial period, but pair it with a secondary model for production workloads until the competitive detection boundaries become clearer.
📚 Learn Claude Code → Claude Code Complete Guide: Setup, Pricing & Best Practices 💰 How Developers Earn With Claude → Claude Code Monetization Case 📖 Related: Claude Opus 4.8 Complete Breakdown