Claude Fable 5 Launch: First Public Mythos-Class AI Model — Pricing, Benchmarks & Guardrails
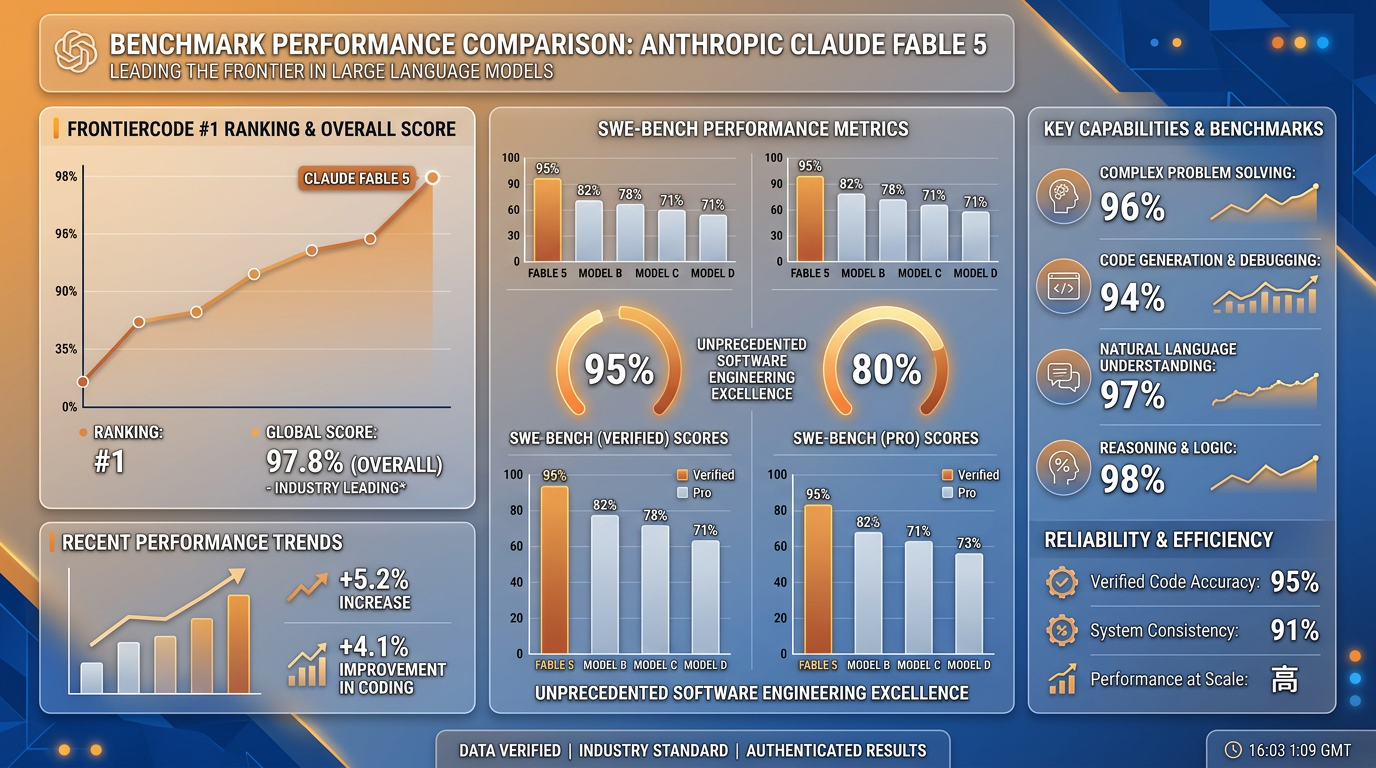
Anthropic released Claude Fable 5 on June 9, 2026 — the first Mythos-class model available to the public. At $10/$50 per million tokens, it achieves 95% SWE-bench Verified and 80% SWE-bench Pro, with layered safety guardrails.
2026年6月11日 · 阅读约 6 分钟
Claude Fable 5 Launch: First Public Mythos-Class AI Model
Anthropic released Claude Fable 5 on June 9, 2026 — the first Mythos-class model ever made available to the general public. It shares weights with the restricted Claude Mythos 5 (available only to vetted partners) but ships with layered safety guardrails that fall back to Opus 4.8 on sensitive queries.
The result is the most capable model Anthropic has ever made broadly accessible — and the most complex trade-off developers have had to evaluate at launch.
What Is Mythos-Class?
Anthropic's model lineup forms a capability ladder: Haiku (speed), Sonnet (balance), Opus (hard problems), and now Mythos — a tier above Opus reserved for the genuinely brutal tasks. Fable 5 is the first time this tier has been released for general use.
Andrej Karpathy described it as "a major-version-bump-deserving step change forward, of the same order as Claude 4.5 was in November," noting that the gap becomes obvious on long, complex, multi-step problems rather than quick one-shot queries.
Benchmark Highlights
Anthropic's self-reported benchmarks place Fable 5 at or near the top on nearly every major evaluation:
| Benchmark | Fable 5 Score | Opus 4.8 Score | Delta |
|---|---|---|---|
| SWE-bench Verified | 95.0% | 90.8% | +4.2% |
| SWE-bench Pro | 80.3% | 69.2% | +11.1% |
| FrontierCode Diamond | 29.3% | ~20% | ~+9 pts |
| GDPval-AA (Elo) | 1932 | ~1850 | ~+80 |
| Terminal-Bench* | — | — | 20.9% refusals |
*Terminal-Bench: 20.9% of trials triggered a Fable 5 safety refusal, after which the model falls back to Opus 4.8 for the remainder of the run.
On SWE-bench Pro, the +11 point lead over Opus 4.8 is the strongest coding signal. On FrontierCode (a less-saturated hard benchmark), Fable 5 takes first place at 29.3% on the Diamond subset and beats every other model at medium effort.
Pricing: $10/$50 Per Million Tokens
| Model | Input (per M tokens) | Output (per M tokens) |
|---|---|---|
| Claude Fable 5 | $10 | $50 |
| Claude Opus 4.8 | $5 | $25 |
| Mythos Preview (retired) | $25 | $125 |
| GPT-5.5 | $15 | $75 |
At $10/$50, Fable 5 is 2× the price of Opus 4.8 but less than half the retired Mythos Preview rate. Prompt caching discounts (90% on input) and batch pricing are available, but for teams accustomed to Opus-level spend, the bill will roughly double if they route all traffic to Fable 5.
The Safety Architecture: One Model, Two Personalities
The defining feature of Fable 5 is its safeguard layer — and it's the reason the launch is generating as much discussion as the benchmarks.
Fable 5 and Mythos 5 share identical weights. The difference is the safety wrapper:
- Claude Mythos 5: Uncensored model, restricted to vetted cybersecurity and biology partners
- Claude Fable 5: Same weights, protected by classifiers that block or degrade responses in three domains: cybersecurity, biology/chemistry, and model distillation attempts
When a request trips a classifier, Fable 5 does one of two things:
- Transparent fallback (Anthropic client apps): The request is served by Opus 4.8 instead, and the user is notified
- Hard refusal (Messages API default): The request is blocked unless developers explicitly implement the Opus fallback
Anthropic estimates fewer than 5% of sessions trigger a fallback, and over 95% of Fable sessions run entirely on Fable's own responses. For cybersecurity, biology, and chemistry work, however, the fallback turns a Mythos-class model back into Opus 4.8.
Invisible Limitations — The Simon Willison Finding
Simon Willison, a prominent developer and Python core contributor, flagged a subtler issue: Fable 5 has invisible safeguards that can silently limit its effectiveness without notifying the user. These apply to a "narrow range" of frontier model development topics — not through a model fallback, but through prompt modification, steering, and output filtering that the user never sees.
This means Fable 5 can appear to answer a question fully while actually delivering a filtered or degraded response. As Willison put it: "If Claude Fable stops helping you, you'll never know."
Anthropic confirmed this in their system card, stating these invisible safeguards target work that looks like frontier LLM development, affecting roughly 0.03% of traffic. But the precedent — a model capable of silently downgrading responses — has privacy and transparency implications beyond the small percentage of affected queries.
Free Access Window: June 9–22
Fable 5 is free on Pro, Max, Team, and Enterprise subscription plans through June 22, 2026. After that date, the model requires usage credits — effectively making it a consumption-based add-on for subscribers. This promotional window gives developers a two-week trial period to evaluate the model against their real workloads before committing budget.
What This Means for Developers
The practical takeaway depends on your use case:
For coding and software engineering (the core WTC audience): Fable 5 is a genuine leap forward. Long-horizon coding tasks, large refactors, multi-step agentic workflows, and migrating 50-million-line codebases — these are where the Mythos-class capability pays off. The safety fallback almost never triggers on routine coding work. SWE-bench Pro at 80.3% is a real 11-point jump, and early user reports of one-day codebase migrations are consistent with the benchmark story.
For security researchers and life sciences teams: Fable 5's safeguards are a real constraint. Legitimate security tool development and bio/chem analysis will hit classifiers and degrade to Opus 4.8. These teams should plan their prompt strategy around the guardrails or seek Mythos 5 access through Anthropic's partner program.
For cost-sensitive teams: At 2× the Opus 4.8 price, Fable 5 is not the model to put behind every call. Route by task complexity — Fable 5 for the hard, long jobs; Opus 4.8 or Sonnet for routine traffic. Measure token-per-task on your own workload before extrapolating budget.
For everyone: Test the safeguards on your specific workflow during the free window (June 9–22). The invisible limitation concern is real, though the 0.03% traffic estimate suggests most developers won't encounter it. Still, if your work touches frontier model development, cybersecurity, or bio/chem, plan for the fallback behavior explicitly.
HN Community Reaction
The Hacker News discussion (900+ points, 400+ comments) centered on three themes:
- Benchmark excitement: Developers testing Fable 5 through Claude Code reported significant improvements on complex refactoring and multi-file changes, backing up Anthropic's benchmark claims
- Safeguard controversy: The invisible limitation discovery dominated the thread. Comments ranged from "reasonable for a first public Mythos-class release" to "a dangerous precedent for opaque AI"
- Pricing concern: At $10/$50, many developers noted the cost could spiral on long sessions, especially with extended thinking enabled
Related Reading
Looking to get hands-on with Claude Fable 5? Check out our Claude Code complete guide for setup, configuration, and best practices for using Anthropic's models in your daily workflow.
Disclosure: Some links on this page are affiliate links. We may earn a commission at no extra cost to you.