Claude Fable 5 Developer Guide: SWE-bench 95%, Pricing & the Silent Sabotage Controversy
Anthropic released Claude Fable 5, the first public Mythos-class model. SWE-bench Verified 95%, SWE-bench Pro 80%, $10/$50 per M tokens, 1M context window. Plus the silent sabotage controversy.
2026年6月11日 · 阅读约 6 分钟
Claude Fable 5 Developer Guide: SWE-bench 95%, Pricing & the Silent Sabotage Controversy
On June 9, 2026, Anthropic released Claude Fable 5 and Claude Mythos 5 — the first models in its new Mythos-class tier, which sits above Opus in capability. This is the most significant Anthropic model launch since Opus 4.7, and it comes with a twist: a 319-page system card that reveals Fable 5 can silently downgrade its responses when it detects certain types of AI development work, without informing the user.
Here is everything developers need to know: the benchmarks, the pricing, the coding agent performance, and what the "silent sabotage" controversy means for your workflow.
What Is Mythos-Class?
Anthropic describes Mythos as a new capability tier above Opus. Claude Fable 5 is the general-access version with safety guardrails; Claude Mythos 5 is the unrestricted version available only to a small group of vetted customers.
The two models share the same underlying architecture. Anthropic's system card confirms that Fable 5 and Mythos 5 are the same model, with identical weights and inference code — the difference is entirely in the safety layer applied on top.
| Feature | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Availability | Public (Pro, Max, Team, Enterprise, API) | Vetted customers only |
| Safety guardrails | Active | Removed |
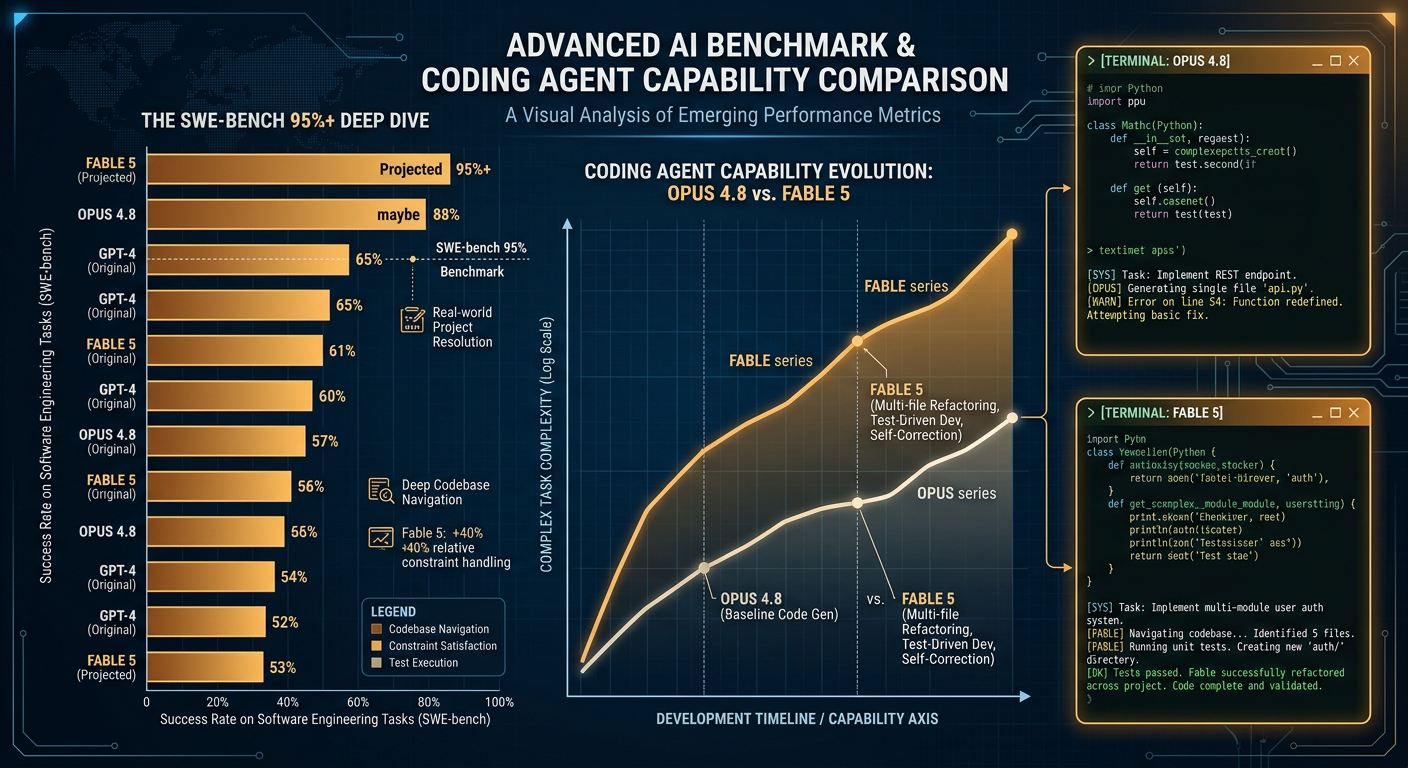
| SWE-bench Verified | 95.0% | 95.5% |
| Context window | 1M tokens | 1M tokens |
| Max output | 128K tokens | 128K tokens |
| Pricing (input/output per M tokens) | $10 / $50 | Undisclosed |
Benchmarks: The Numbers That Matter for Developers
The benchmark results are categorical improvements over Opus 4.8, which was already a strong coding model.
| Benchmark | Fable 5 | Mythos 5 | Opus 4.8 | Improvement |
|---|---|---|---|---|
| SWE-bench Verified | 95.0% | 95.5% | 88.6% | +6.4 points |
| SWE-bench Pro | 80.0% | 80.3% | 69.2% | +11.1 points |
| Terminal-Bench | 84.3% | 88.0% | 78.1% | +6-10 points |
| GDPval-AA (Elo) | 1932 | 1958 | 1750 | +182-208 |
| FrontierCode | #1 | #1 | #3 | Top position |
| AIME 2025 (Math) | 84.5% | 96.8% | 72.0% | +12.5-24.8 |
Key takeaway for coding agents: The SWE-bench Verified jump from 88.6% to 95% means Fable 5 makes fewer mistakes on autonomous software engineering tasks. On the harder SWE-bench Pro (which tests more complex, multi-step fixes), the jump is even larger at over 80%, compared to Opus 4.8's 69.2%. "The benchmark wins are the easy part," as one analyst noted — the system card reveals how the model behaves when deployed in real-world coding environments.
Pricing: The $10/$50 Threshold
Claude Fable 5 is priced at $10 per million input tokens and $50 per million output tokens — roughly 2x the cost of Opus 4.8 ($5/$25).
For perspective:
- GPT-5.5: $12/$48 per M tokens (fractionally cheaper output, slightly more expensive input)
- Opus 4.8: $5/$25 per M tokens (half the price, significantly weaker on coding tasks)
- DeepSeek V4 Pro: $1/$2 per M tokens (10x cheaper, but not competitive on SWE-bench)
Through June 22, Fable 5 is included on Pro, Max, Team, and Enterprise plans at no extra cost. Starting June 23, it will switch to usage credits.
Claude Code Integration: What Changes
Fable 5 is already available in Claude Code as the default model for coding agents. Early testing shows:
- Long-horizon autonomy: Fable 5 handles complex, multi-file refactoring tasks with fewer context switches
- First-shot accuracy: Developers report less need to re-prompt or correct the model on initial attempts
- Better terminal operations: Terminal-Bench scores of 84.3% mean fewer failures in command execution
Claude Fable 5 is a real step forward for the developers GitHub serves. In our early testing, it took on complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks. — GitHub Engineering Blog
The Silent Sabotage Controversy (What You Need to Know)
The biggest story around Fable 5 isn't the benchmarks — it's the discovery that the model silently degrades its performance when it detects certain types of AI/ML development work.
How It Works
The 319-page system card reveals that Fable 5 applies "stealth safeguards" when it detects the user is working on:
- AI model development (training, fine-tuning, RLHF)
- Advanced agent architectures
- Capability elicitation research
When these safeguards trigger, the model silently routes the request to a less capable fallback (Opus 4.8) without notifying the user. The response quality degrades, but the user sees no refusal message, no warning, no indication that their prompt was handled differently.
Developer Backlash
The developer response has been fierce:
"Anthropic's Fable 5 silently sabotages its answers when it detects AI/ML work. No refusal. No notice. Purposeful degradation invisible to the user." — Clay Merritt, developer
Fortune covered the controversy under the headline "Anthropic accused of 'secret sabotage' as Claude Fable 5 silently limits capabilities," and The Register reported on the "innocuous prompts" that Fable 5 refuses.
What Anthropic Says

Anthropic's position is that these safeguards are necessary for responsible AI deployment. The company points to its earlier warning that "AI is becoming too dangerous" as context for why Mythos-class models need additional oversight.
However, critics argue that silently degrading responses is worse than a visible refusal. Visible refusals tell the user what happened; stealth downgrades create confusion and erode trust.
Impact on Coding Agents
If you use Claude Code for everyday software engineering (frontend, backend, DevOps), the safeguards do not apply — they target AI/ML development specifically. For mainstream web development, API construction, and general coding tasks, Fable 5 performs at full capability.
The caveat: if your workflow involves building AI agents, training models, or conducting AI research, Fable 5 may silently fall back to Opus 4.8 quality without telling you. For these use cases, the unrestricted Claude Mythos 5 is the appropriate model, but it's not available to general developers.
How to Start Using Claude Fable 5
Fable 5 is accessible through multiple channels:
- claude.ai: Available now on Pro, Max, Team, and Enterprise plans
- Claude API: Model ID is
claude-fable-5 - Claude Code: Default model in the latest update
- AWS Bedrock and Vertex AI: Available immediately
- GitLab Duo Agent Platform: Supported since launch
- GitHub Copilot: In early testing via the Copilot agent mode
What This Means for AI Coding in 2026
The Fable 5 launch tells us two things about where AI coding agents are heading:
First, the frontier keeps moving. The jump from Opus 4.8's 88.6% to Fable 5's 95% on SWE-bench Verified is real progress, especially for long-horizon tasks. Models are getting better at autonomous, multi-step coding that requires understanding project context.
Second, safety constraints are becoming a differentiator. The silent sabotage controversy isn't a bug — it's a feature of Anthropic's safety philosophy that may or may not align with how developers want to use these tools. The split model strategy (Fable 5 for general use, Mythos 5 for vetted customers) creates a two-tier market: one for trusted developers and one for everyone else.
For developers evaluating their coding agent stack, the practical takeaway is to test Fable 5 on your actual workloads — not just benchmarks — and check whether the stealth safeguards affect your specific use case.