Anthropic 同日双响炮:AI 自我进化路线图 + 开源漏洞框架
Anthropic 同日发布两份重磅材料:AI 研究所报告首次披露内部数据(80% 代码由 AI 编写、人均产出提升 8 倍、研究判断首次超越人类),以及开源 AI 驱动漏洞自动发现与修复框架。AI 的自我加速和安全守护同时发生。
2026年6月5日 · 阅读约 12 分钟
核心结论
2026 年 6 月 5 日,Anthropic 在同一天发布了两份重量级材料,分别从发展速度和安全保障两个维度刻画 AI 行业当前的交汇点。
- 《When AI Builds Itself》(Anthropic Institute 报告,HN 383 分 / 509 条评论):首次披露内部数据——Anthropic 80% 以上的代码由 Claude 编写,人均代码产出较 2024 年提升 8 倍,研究判断已首次超越人类。
- Defending Code Reference Harness(开源框架,HN 320 分 / 102 条评论):一套完整的 AI 驱动漏洞发现与修复管线,供安全团队将 Claude 部署为自主漏洞猎人。
两篇材料的叠加信号清晰:AI 正在同时加速自身进化,也正在学习如何守护自身安全。 对于 WayToClawEarn 的读者(AI Agent 用户、自动化从业者),这意味着两件事——你的 AI Agent 很快会变得更聪明(更高成功率、更长自主时长),但同时,AI Agent 安全不可忽视。
关键要点
- 事件发生时间:2026-06-05
- 影响对象:AI 开发者、安全团队、AI Agent 自动化用户
- 核心变化:AI 的自我进化正在从"人写代码→AI 辅助"升级为"AI 写代码→人做判断→AI 做判断",同时 AI Agent 安全从可选升级为必备
背景:同一个周一,两个方向
6 月 5 日,Anthropic 研究部门 Anthropic Institute 发布了其首份重磅研究报告《When AI Builds Itself》,详细记录了 AI 系统内部开发数据的惊人变化。同日,Anthropic 的 Claude Security 团队在 GitHub 上开源了 Defending Code Reference Harness,将他们在 Project Glasswing 中已验证的自动漏洞发现方法论完整开放。
前者来自研究部门,指向能力上限;后者来自安全部门,指向防护底线。两条脉络曾在同一家公司交汇,而它们的共同结论是:AI 必须既能变强,又被控制。
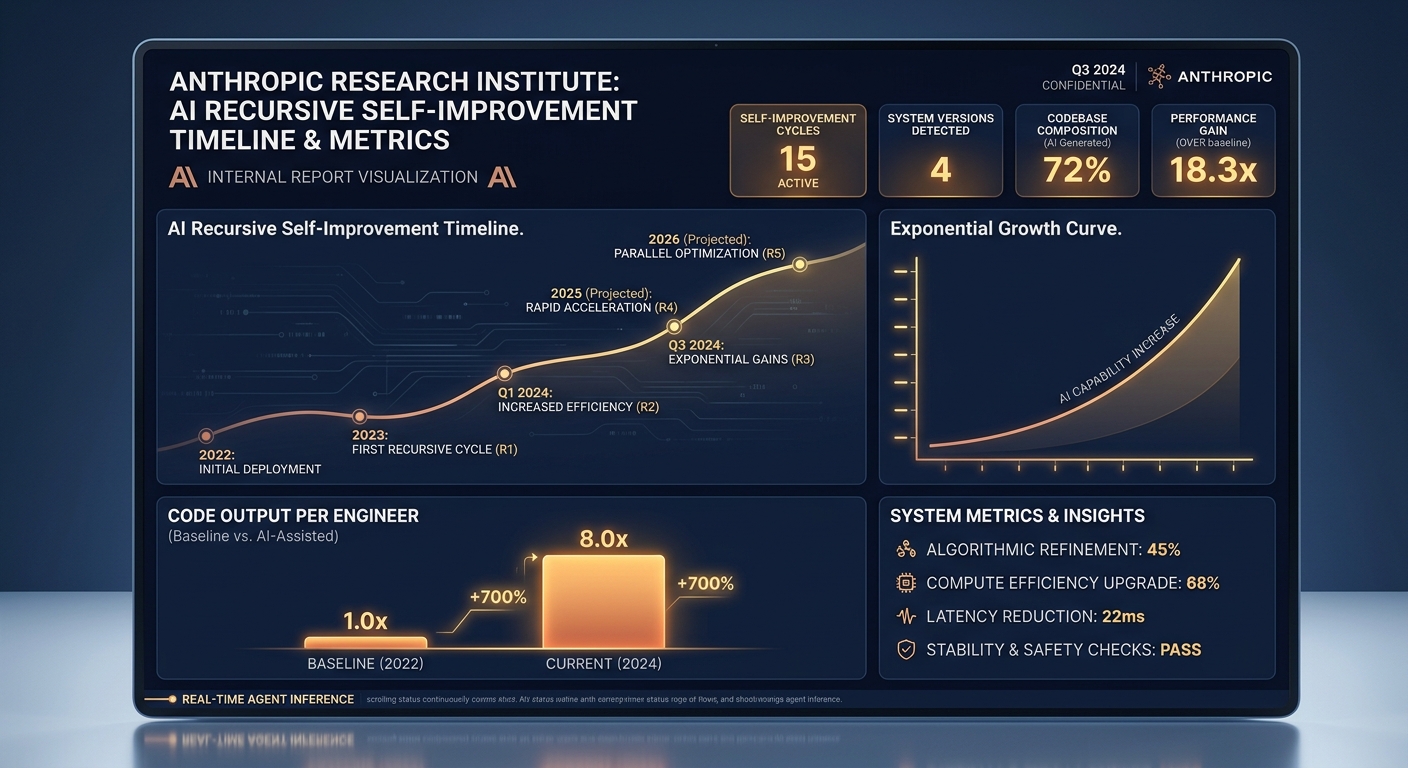
故事一:AI 正在自我进化——Anthropic 内部数据首次公开
Anthropic Institute 的报告提供了此前从未公开的内部数据,展示了 AI 在推动 AI 开发方面的实际渗透率。
工程效率:从 1x 到 8x
报告显示,2021 年至 2024 年,Anthropic 每位工程师每天合并的代码行数保持稳定。2025 年初 Claude Code 上线后,这一数字开始攀升。2026 年第二季度,典型工程师的日均产出较 2024 年提升了 8 倍。
这 8 倍的提升并非来自工程师工作更努力,而是因为大部分代码由 Claude 编写,工程师的角色从"打字员"转向"审阅者"。报告特别指出,行数是衡量代码"量"的粗略指标,真实生产力提升"几乎肯定低于 8 倍",但主观感受同样引人注目——在一项对 130 名研究团队员工的调查中,中位数受访者估计他们的产出约为无 AI 支持时的 4 倍。
代码质量:从需修正到已接近人类水平
报告将"好代码"定义为两个维度:它是否能运行,以及其他人是否能理解和改进它。
在第一个维度上,Claude 的表现持续改善。工程师纠正、中断或接管 Claude 的频率在过去一年持续下降,甚至在最复杂、最开放的任务上也如此。2026 年 5 月,Claude 在完全开放式任务上(即问题没有明确规范,工程师也不确定答案)的成功率达到 76%,较半年前提升了 50 个百分点。
在第二个维度(代码可读性和可维护性)上,报告承认 Claude 写的代码在 2025 年末仍低于人类工程师,但"今天大致持平",并预测"一年内将超越人类"。
研究能力:从执行到判断
最引人注目的数据来自研究能力。报告引用了一项内部测试:给 Claude 一个需要优化的微模型训练代码,Claude Opus 4 在 2025 年 5 月能实现大约 3 倍的速度提升;到 2026 年 4 月,Mythos Preview 实现了大约 52 倍的速度提升。
当实验变为开放式的——Claude 须自己提出假设、设计实验、并迭代——它的表现同样超出预期。2026 年 4 月,Anthropic 发布了首个 Claude 端到端自主完成 AI 安全研究的实验:两个人类研究员花大约一周时间恢复了一个问题约 23% 的差距;Claude Agent 在 800 小时的自动工作中恢复了 97% 的差距,使用的算力成本约 $18,000。
最令人惊讶的是研究判断力的进展。报告选取了 129 个"人类研究者实际做出了非最优选择"的时刻,让模型来判断"如果当时是我,下一步做什么"。2025 年 11 月,Claude Opus 4.5 在 51% 的时间里优于人类选择;2026 年 4 月,Mythos Preview 提升到了 64%。
评论:当 AI 的研究判断首次超过人类时,过去所有关于"人类会保留研究方向选择权"的假设都需要重新审视。
自动化代码审查:回溯发现,1/3 的事故本可避免
报告末尾提到一个引人深思的数据:Anthropic 开发了一个自动 Claude 代码审查工具,在每次合并前扫描 bug 和安全缺陷。回溯分析发现,如果这个工具在历史上一直被使用,Claude.ai 的大约 1/3 的事故本可在上线前被捕获。
工程师自豪地补充了一个案例:2026 年 4 月,Claude 自动修复了 800 多个 API 错误,将类错误的出现频率降低了 1000 倍。工程师估计人类需要 4 年才能完成这项工作。
三个未来场景
报告最后列出了三种可能的未来:
- 渐进加速:如果 AI 的研究判断永远无法超越人类,但人类只做方向决策、AI 做其余所有工作——这本身已是大幅加速
- 临界点:AI 判断达到人类水平,进入完全自动化研发循环
- 放缓与协调:有意识地放慢开发速度,以换取安全和社会基础设施的同步发展
Anthropic 明确表示:如果存在可信的全球协调机制,他们"会放慢或暂停"前沿 AI 开发。
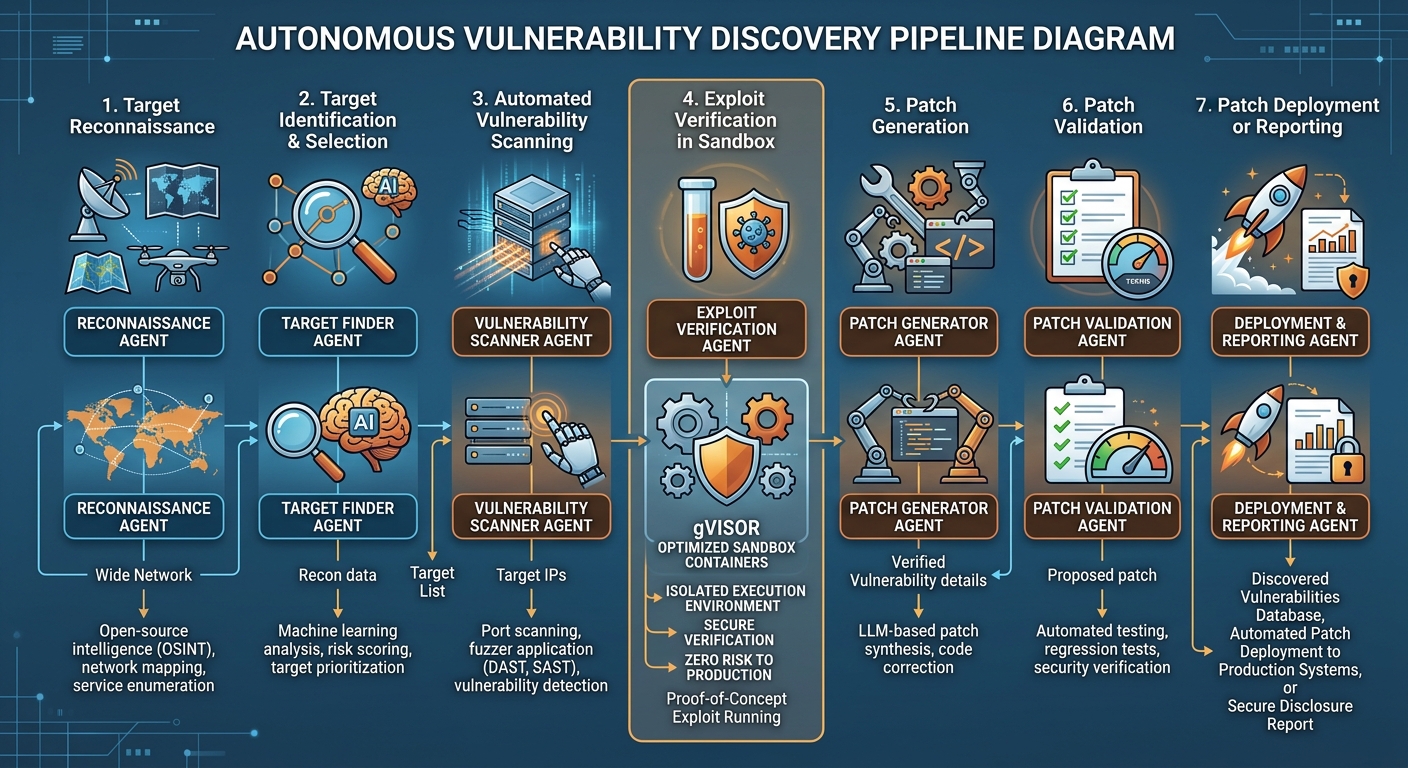
故事二:开源自动漏洞发现框架——AI 成为自己的安全守护者
同一天,Anthropic 在 GitHub 上开源了 Defending Code Reference Harness,一套完整的 AI 驱动漏洞发现与修复管线参考实现。
从 Project Glasswing 到开源参考
这套框架基于 Anthropic 自 Claude Mythos Preview 发布以来与多个安全团队合作的经验。它不是一个产品(产品版本是 Claude Security),而是一套可定制、可扩展的参考实现,安全团队可以基于它部署自己的 AI 安全管线。
GitHub 仓库包含:
- Claude Code 交互式技能:
/quickstart、/threat-model、/vuln-scan、/triage、/patch、/customize - 自主管线(harness/):完整的 recon → find → verify → report → patch 自动化循环
- gVisor 沙箱:Agent 在隔离容器中运行,出口流量仅限于 Claude API
七阶段管线:从构建到修复
管线包含 7 个连续阶段:
- 构建(Build):将目标编译为带有 ASAN(内存错误检测器)的 Docker 镜像
- 侦察(Recon):轻量级 Agent 分析源代码,建议 N 个值得独立攻击的输入解析子系统
- 发现(Find):N 个 Agent 并行运行,各自构建畸形输入并测试,直到某个输入 3 次触发崩溃
- 验证(Verify):独立的评分 Agent 在全新容器中重现每个崩溃
- 去重(Dedupe):法官 Agent 比较已验证的崩溃,区分新 bug、已知 bug 的更好案例和重复项
- 报告(Report):为每个独特 bug 编写结构化的可利用性分析
- 修复(Patch):独立的修复 Agent 编写修复代码,评分 Agent 验证新代码构建通过、测试通过
全栈安全:从静态扫描到自主修复
框架支持两种模式。交互模式仅读/写文件,在 Claude Code 中逐步骤操作,适合第一天快速上手。自主模式需要 gVisor 沙箱,Agent 获得执行权限后被限制在隔离容器中,出口仅限 Claude API。
Anthropic 推荐的部署节奏是:
- 第 1 天:构建威胁模型 + 运行静态扫描 + 分类结果
- 第 2 天:在已知漏洞的开源库上运行参考管线
- 第 3-5 天:为你的目标代码库定制管线
- 第 2 周:开始全自主扫描、分类和修复
为什么这对你很重要
对于使用 AI Agent 进行自动化开发和运营的团队,这个框架意味着三件事:
- 安全不再是瓶颈:AI Agent 写出的代码可以用另一个 AI Agent 专门审查
- 漏洞发现可规模化:不再依赖安全团队手动代码审计
- AI Agent 安全是必备品:如果 AI 8x 加速了开发,那 AI 产生的漏洞量也以类似倍数增长
社区反应:HN 的两极视角
在 HN 上,509 条评论围绕《When AI Builds Itself》展开了激烈的层次讨论:
- 肯定派认为 8x 产出提升和 64% 的研究判断准确率是"不可忽视的信号"。有评论指出:"如果 Anthropic 内部 80% 的代码已是 AI 写的,这个数字只会增长,直到那 20% 也被取代"。
- 怀疑派则质疑"行数"这个指标本身。"更多代码不等于更好代码。AI 更擅长产生量,但产生一个坏决策的速度也更快",一位 HN 用户评论道。
- 务实派聚焦于"研究判断"数据。有用户指出"64% 选对了 36% 处错误"意味着判断力报告还需要以不同形式重复验证,现阶段远不能断言 AI 可完全自主做研究决策。
在 Defending Code 话题下,102 条评论更多倾向于实用性。多位安全从业者肯定了开源的价值,尤其是 gVisor 沙箱的设计和七天部署路线图。
两件事放在一起看
单独看,每一篇都是独立的好文章。放在一起看,它们讲述了同一个故事——AI 行业正在进入一个自我加速和自我守护的双重循环。
| 维度 | 《When AI Builds Itself》 | Defending Code Reference Harness |
|---|---|---|
| 定位 | 能力上限报告 | 安全防护工具 |
| 目标读者 | AI 战略决策者、研发团队 | 安全团队、DevOps 工程师 |
| 核心数字 | 80% AI 代码、8x 产出、64% 判断 | 7 阶段自主管线、gVisor 沙箱 |
| 对 WTC 读者的意义 | 你的 AI Agent 将更快变强 | 你的 AI Agent 安全不可忽视 |
| HN 社区反应 | 383 分 / 509 条,两极争论 | 320 分 / 102 条,务实讨论 |
下一步行动:3 条实操建议
-
了解你的 AI Agent 的自主权:如果你在用 Claude Code、Codex 或任意 AI 编程工具,确认它不会在没有审查的情况下合并代码。Anthropic 自己的数据显示,AI 产生的代码中约 1/3 的事故本可在审查中拦截。
-
尝试开源安全框架:Defending Code Reference Harness 是真正可运行的。从 Step 1(威胁模型 + 静态扫描)开始,30 分钟可以走完。如果你在用 AI 做自动化开发,这就是你的必备工具链。
-
评估你的 AI Agent 是否需要用沙箱:如果你的 AI Agent 有执行权限(如运行代码、操作文件),考虑引入 Anthropic 类似的 gVisor 隔离。这不是只有大公司才需要考虑的问题——一个被污染的 prompt 可以导致任何 AI Agent 做出不可预测的行为。
相关阅读
- 想动手试试?看教程:如何用 Anthropic 开源框架搭建 AI 漏洞自动发现与修复管线:30 分钟完整教程
- 真实案例:安全研究员用 Claude Code 做漏洞挖掘:月入 $10,000 的真实案例
- AI Agent 安全入门:AI 编程 Agent 安全配置教程:3 步给 Claude Code/Codex 加权限沙箱
来源:Anthropic Institute + GitHub + Hacker News