Anthropic公布AI自进化路线图:80%代码AI编写,研究判断首次超越人类
Anthropic Institute 首次公开内部数据:80%+代码由Claude编写,工程师人均产出提升8倍,AI研究判断首次超越人类。递归自我改进不再是理论,正在Anthropic内部发生。
2026年6月5日 · 阅读约 9 分钟
核心结论
6月4日,Anthropic Institute 发布重磅报告《When AI Builds Itself》,首次公开公司内部的 AI 自进化数据。核心发现:AI 正在以远超公开认知的速度驱动自身进步——Anthropic 工程师人均产出已提升 8 倍,80% 以上的代码由 Claude 编写,AI 在研究判断上首次超越人类基线(64% vs 51%)。
| 关键指标 | 数据 | 时间点 |
|---|---|---|
| 工程师人均代码产出 | 8x 提升 | 2026 Q2 vs 2024 |
| Claude 编写的合并代码占比 | 80%+ | 2026年5月 |
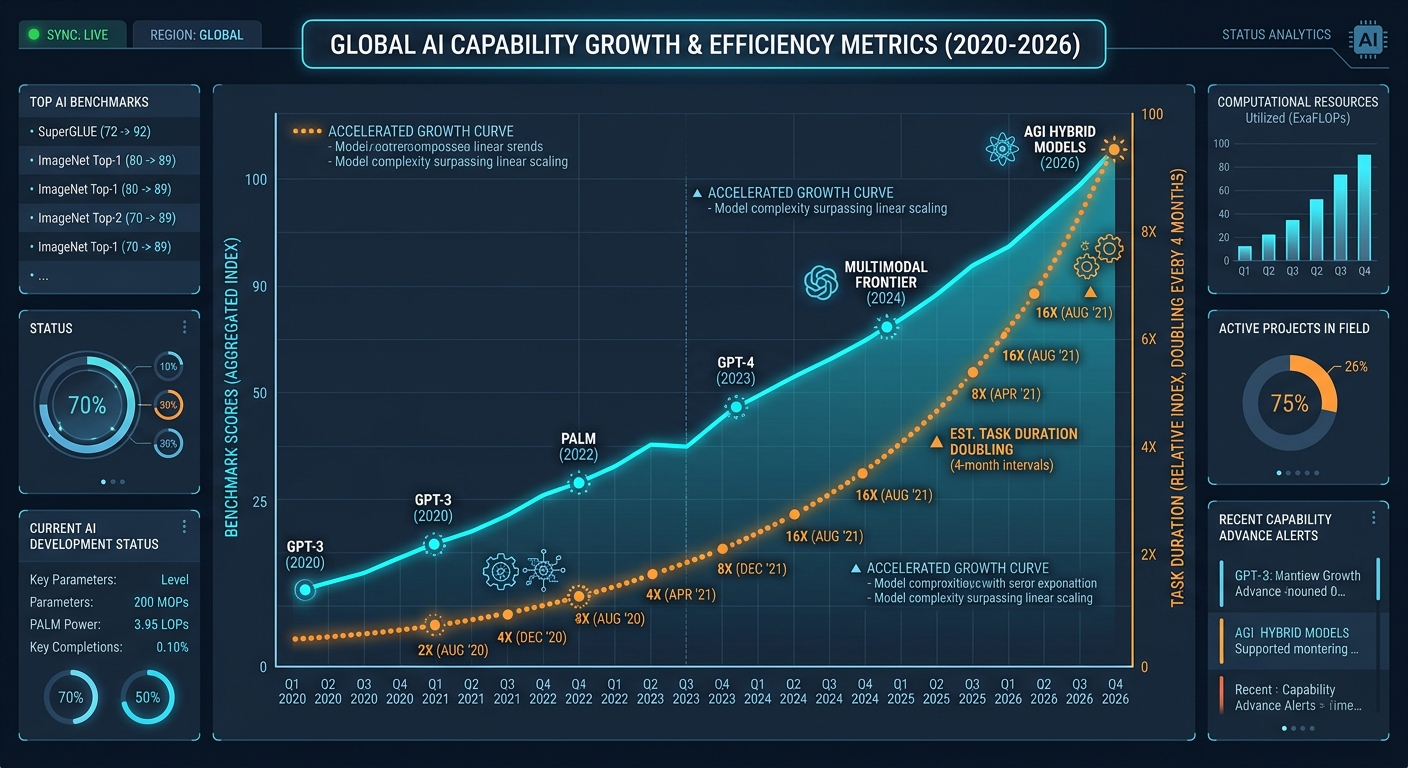
| 任务时长翻倍周期 | 每4个月(此前每7个月) | 2025-2026 |
| 开放式研究任务成功率 | 76%(+50pp in 6mo) | 2026年5月 |
| AI 研究判断 vs 人类基线 | 64% 胜率(此前51%) | 2026年4月 vs 2025年11月 |
这篇文章不是理论推演——每一条数据都来自 Anthropic 内部的工程和研究实践。
背景:从"人类从头写"到"AI 参与每一步
Anthropic 将 AI 开发流程分为三阶段演变:
- 早期(2021-2024):人类写代码、人类调试、人类部署。AI 只是偶尔生成短代码片段,工程师手动复制粘贴
- 中期(2025):Claude Code 发布后,AI 开始自主编写和编辑整个文件。人均代码产出开始拐点向上
- 当前(2026):AI Agent 可以自主运行代码、委托任务给其他 Agent、持续工作数小时。关键转折:人类不再写大部分代码,而是担任"设定目标+审查"的角色
Anthropic 的研究员 Marina Favaro 和 Jack Clark 联合撰写了这份报告,明确指出:"如果我们认为趋势会持续,那么 AI 完全自主设计自身继任者的能力(递归自我改进)可能比大多数机构准备的时间来得更早。"
AI 任务能力的指数级增长
报告中最引人注目的数据是 AI 任务长度的增长曲线:
2024年3月,Claude Opus 3 可完成约4分钟的人类软件任务。一年后,Claude Sonnet 3.7 管理了约1.5小时的任务。又过了一年,Claude Opus 4.6 完成了12小时的任务。
趋势:可可靠完成的任务时长每4个月翻一番(此前为每7个月)。按此趋势:
- 2026年内:持续数天的任务进入能力范围
- 2027年:持续数周的任务成为可能
在基准测试方面同样如此。SWE-bench(真实软件工程能力测试)上,AI 模型从个位数得分到达到满分的饱和点,仅用了两年时间。CORE-Bench(研究复现能力测试)上,AI 在 2024 年只能复现约 20% 的研究结果,15个月后就达到了基准饱和点。
内部工程数据:80% 代码由 Claude 编写
这是报告的核心部分——Anthropic 首次公开了内部工程指标:
代码产出:
- 2021-2024年:人均合并代码量保持恒定
- 2025年初(Claude Code 发布后):曲线开始攀升
- 2026年Q2:典型工程师每日合并 8x 的代码量
代码质量:
- 2025年底:Claude 编写代码的质量仍低于人类
- 2026年中:与人类持平
- 预计一年内:超越人类
"我们对代码库的每个变更现在都由自动化 Claude 审查者检查 bug、安全缺陷和其他缺陷。回顾分析发现,如果对所有历史变更使用 Claude Code Review,能捕获约三分之一的过去生产事故。"
代码介入率(工程师需要中途修正/接管 AI 的比例):
- 过去一年持续下降
- 最开放式任务的成功率在6个月内提升了50个百分点(从 26% 到 76%)
一个典型案例:某次例行的训练集群升级导致数万个训练任务崩溃。工程师仅给 Claude 提供了集群访问权限和一些文本上下文。Claude 逐一排查运行中的任务,逐个测试环境变量,最终定位到一个晦涩的调试标志触发崩溃——完成了通常需要 2-3 天的调试工作,仅用了约2小时。
"机器人纠正错误"的经典场景正在倒转——现在人类设定的目标,Claude 给出方法。人类不再需要提供实现细节。
研究能力:从实验执行到实验设计
Anthropic 在内部测试了 Claude 的研究能力,跨越三个层级:
层级1:执行指定实验(最擅长)
- 给 Claude 一段训练小模型的代码,要求优化速度
- 2025年5月:Claude Opus 4 实现约 3x 加速
- 2026年4月:Claude Mythos Preview 实现约 52x 加速
- 对比:人类研究员需要 4-8 小时才能达到 4x
层级2:自主设计实验路径
- 2026年4月:Anthropic 首次公开演示 Claude 端到端运行开放式研究项目
- 任务:弱模型能否可靠监督强模型?(AI 安全核心问题)
- 结果:人类研究员约 1 周恢复约 23% 的性能差距;Claude Agent 在 800 累计小时内恢复 97%,使用约 $18,000 的计算资源
- 局限:结果未完全迁移到生产规模模型,人类仍负责设定问题和评分标准
层级3:研究判断(最关键的进步)
- Anthropic 设计了一个独特实验:从 129 个真实的 Claude Code 会话中提取了"人类研究员走弯路"的时刻
- 展示这些时刻给 Claude,问它"下一步该做什么"
- 2025年11月(Opus 4.5):AI 判断优于人类 51%(几乎随机)
- 2026年4月(Mythos Preview):AI 判断优于人类 64%
- 这是首次公开证据表明 AI 在"下一步研究决策"上超越了人类
AI 加速开发循环:三个未来场景
Anthropic 指出了 AI 自进化的三个可能未来:
| 场景 | 描述 | 可能性 | 风险 |
|---|---|---|---|
| 分步自动化 | AI 加速执行,人类保留方向判断 | 最可能 | AI 开发速度远超治理体系适应 |
| 全自治研发 | AI 自主设计、执行、迭代研究 | 可能(趋势持续下) | 人类失去对 AI 进化速度的控制 |
| 全球协调放缓 | 多方协议限制前沿 AI 进展 | 最优但最困难 | 缺乏可信的验证机制,作弊者占优 |
Anthropic 明确表示:"我们相信如果可能有效减缓这项技术的发展以给自己更多时间处理其巨大影响,这很可能是一件好事。但减缓意味着全球协调机制——而我们现在没有。"
HN 社区反应:两面夹击
这篇报告在 Hacker News 获得 294 分和 380 条评论,社区反应呈现两极:
批评派:
- 有用户指出:"如果 Anthropic 的 AI 真这么厉害,为什么他们还在面临定期 outage?API 错误 'Server is temporarily limiting requests' 已成为常态。"
- 另一位质疑:"从 vibe coding 开始,除了 vibe coding 本身之外,没有任何软件突破。将 Zig 程序重写为不安全的 Rust?不是突破。"
- "一个不能构建低于 1GB 内存的终端应用程序的公司,谈什么递归自我改进?"
安全关切派:
- "我看不出全速追求递归自我改进与 Anthropic 宣称的 AI 安全目标如何兼容。如果核武器还没被发明,你会以最快速度建造并销售它们吗?"
对 AI Agent 用户的实操启示
这篇报告中的数据对任何使用 AI Agent 做生产力工具的人都有直接影响:
- Agent 任务时长窗口正在快速扩大:如果你的工作流依赖 AI Agent 处理数小时的任务,现在可以规划到天级的自主工作流。2027 年可能扩展到周级
- 审查效率成为新瓶颈:Anthropic 明确警告"如果人类审查跟不上 AI 生成速度,审查将变成瓶颈"。建议提前建立自动化审查管线(Claude Code Review 方向)
- 开放式问题的委托时机成熟:当研究判断 AI 胜率达到 64%,意味着 AI 在"下一步做什么"这类决策上已经可信任。尝试将模糊问题("这段代码为什么慢"、"这个bug的根因在哪")直接委托给 AI
反直觉的结论:AI 自己的数据表明,AI 研发正在快速自动化——但自动化的方向不是"AI 取代工程师",而是"每个工程师管理更多 AI 工作流"。对 WTC 读者来说,这意味着:学会用 AI 管理 AI 工作流的能力,比学会写更快代码更重要。
相关阅读
- 想学 AI Agent 自动化工作流?看:AI 编码 Agent 技术选型指南:语言、模型、成本三维决策
- 真实案例:用 Claude Code 搭建自动化测试流程
- 推荐工具:Claude Code | Anthropic | OpenAI | DeepSeek