Google 发布 Gemma 4 12B:无编码器多模态模型,16GB 笔记本即可本地运行
Google 发布 Gemma 4 12B,无编码器多模态架构可在 16GB 笔记本运行,内置 Multi-Token Prediction 推测解码,Apache 2.0 开源。
2026年6月4日 · 阅读约 7 分钟
核心结论
6月3日,Google 发布 Gemma 4 12B,一款专为本地部署设计的无编码器多模态模型。它能在16GB RAM的消费级笔记本上运行,采用全新的"无编码器"架构——去掉了独立的视觉和音频编码器,让数据直接流入大模型骨干网络。配合 Multi-Token Prediction (MTP) 推测解码,推理速度和效率都显著提升。
这对 AI Agent 开发者意味着:你可以把多模态能力(看图、听音频)直接跑在本地笔记本上,不需要 GPU 服务器,不需要 API 调用,甚至不需要第三方编码器。Agent 的感知层和推理层首次可以在一个模型内完成。
关键要点
- 时间:2026年6月3日
- 参数规模:12B,FP16 权重 ~18GB,在 16GB VRAM/RAM 设备上可用
- 架构创新:无视觉编码器、无音频编码器——输入直接注入 LLM 骨干
- 推理加速:内置 Multi-Token Prediction (MTP) 推测解码,无需额外配置
- 许可证:Apache 2.0,权重即日在 Hugging Face 和 Kaggle 开放下载
背景:Gemma 产品线中的空白终于被填补
2026年4月,Google 发布了 Gemma 4 系列四款模型,标志着 Google 转向更开放的 Apache 2.0 许可证。初始产品线包括:
| 型号 | 参数 | 定位 | RAM 需求 |
|---|---|---|---|
| E2B / E4B | 待定 | 移动端优化 | 低 |
| Gemma 4 12B 🆕 | 12B | 本地笔记本 | 16GB |
| 26B MoE | 26B(活跃参数~9B) | 高精度任务 | ~32GB |
| 31B Dense | 31B | 服务器级 | ~64GB+ |
不难看出,E4B 和 26B MoE 之间存在明显的空白区。12B 参数恰到好处——比移动端模型强得多,又不需要专门的 AI 加速器。这就是 Gemma 4 12B 要填补的位置。
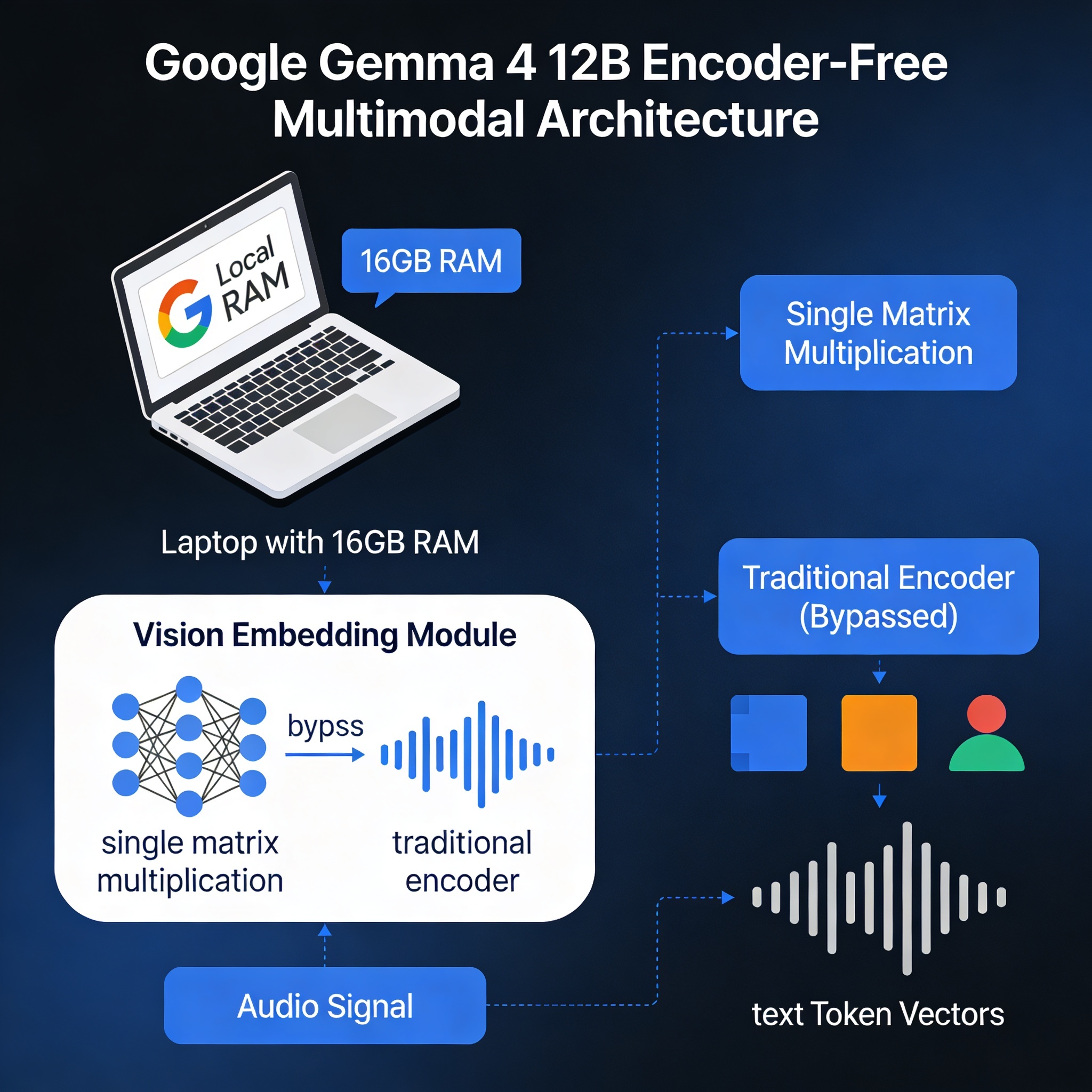
架构突破:为什么"无编码器"是大事
大多数多模态 AI 模型(包括 Gemma 4 系列的其他成员)使用独立的编码器来处理非文本输入。视觉编码器(如 ViT)将图像转换为特征向量,音频编码器对声音做同样的处理,然后这些向量被传入 LLM。这套方案有效,但代价是延迟增加和内存占用上升。
Gemma 4 12B 走了完全不同的路:
视觉方向:用一个轻量级嵌入模块替代视觉编码器,包含单次矩阵乘法、位置嵌入和归一化处理。在保证空间感知能力的前提下,去掉了笨重的"中间人"编码器。
音频方向:更大胆——完全没有编码。团队找到了将原始音频信号直接投影到文本 Token 向量空间的方法。这意味着音频输入像文本 Token 一样"原生"进入模型。
HN 社区评价(minimaxir):"关键创新在于无编码器部分。用单次矩阵乘法替代视觉编码器,更轻量、更高效。"
Multi-Token Prediction:利用闲置计算周期加速
Gemma 4 12B 是 Gemma 4 系列中首个预置 Multi-Token Prediction (MTP) 推测解码的模型。
传统大模型每次只预测一个 Token,这个过程中 GPU 的计算单元并未完全用满。MTP 的思路是:利用闲置的计算能力,同时推测后续多个可能 Token,然后快速验证。如果推测正确,一次计算就能输出多个 Token,推理吞吐量大幅提升。
Google 还为其他 Gemma 4 模型发布了可选的 MTP 版本,但 12B 是出厂自带的。
本地部署:16GB 就够了
Google 表示 Gemma 4 12B 在大多数消费级笔记本上可直接运行,无需昂贵的 AI 加速器。条件是系统 RAM 或 VRAM 达到 16GB——这覆盖了大量 MacBook Pro、高端 Windows 笔记本和部分游戏本。
| 硬件 | 可行性 | 方式 |
|---|---|---|
| MacBook Pro M系列(16GB+) | ✅ 原生 | Ollama / MLX |
| Windows 笔记本(16GB+) | ✅ 运行 | LM Studio / Ollama |
| Linux 桌面(16GB VRAM) | ✅ 最优 | 直接下载权重 |
| 8GB 设备 | ❌ 不可行 | 内存不足 |
HN 讨论中 ComputerGuru 指出:"12B 模型正好填补了 Gemma 4 4B 和 26B 之间的巨大空白。能舒适地装入 16GB VRAM(留出上下文空间),是一个受欢迎的升级。"
HN 社区反应:实用主义主导
629 分、43 条评论的 HN 讨论呈现出几个鲜明立场:
编码器消除是真正的创新 — 多位 HN 用户关注到无编码器架构,认为这是比单纯的"又一个小模型"更有技术含量的创新。
对 16GB 门槛的提醒 — digdugdirk 指出:"每个人都有一台 16GB VRAM 笔记本"的假设对大多数消费者不成立。这是一次对"设备可及性"的清醒提醒。
商业模式质疑 — ethanpil 问道:"Google 发布开源模型的商业逻辑是什么?"这表明即使在社区中,Google 作为一家广告公司发布开源模型仍然让人困惑。常见解读是:通过开源建立开发者生态,最终反哺其 SaaS 和云业务。
与 Gemma 4 26B MoE 的竞争 — Havoc 分析:"MoE 版本在分数上表现更好,且活跃参数更少所以推理更快。12B 真正有意义的是那些内存极度受限的场景,装不下量化后的 MoE。"
对 AI Agent 开发的实操启示
1. Agent 的多模态感知层首次可以本地化
过去需要在云端调用 API 做图像识别、音频处理。现在 Gemma 4 12B 在一个模型内同时完成感知和推理。这对本地 Agent、隐私敏感场景、离线工作流是质变。
2. 推理效率的 MTP 红利
如果你用 Ollama 或 LM Studio 部署 Gemma 4 12B,MTP 在推理时自动生效。不需要额外配置。对于 Agent 的链式调用(Chain-of-Thought)、多步推理场景,MTP 的推测式加速效果更明显——Agent 的一次完整推理可能需要几十个 Token,MTP 的推测命中率在长序列中更高。
3. 16GB 设备的 Agent 部署成为现实
对于需要在客户笔记本上运行 AI Agent 的场景(如本地客服助手、隐私数据处理的 Agent),之前要么用更小的模型牺牲能力,要么依赖云端 API。现在 12B 参数量的多模态 Agent 可以直接部署在大多数开发者和早期用户的笔记本上。
4. 开源模型生态的分化信号
Google 的 Gemma 4 产品线正在呈现明确的分层策略:E2B(移动端)→ 12B(笔记本)→ 26B MoE(工作站)→ 31B(服务器)。这种分层的存在意味着 Agent 开发者可以基于"设备能力"选择对应规模的模型,而非所有场景都调用同一个大模型。
工具词条
本文涉及的工具和平台:Ollama、LM Studio、Hugging Face、Google、MLX、Kagle