阿里巴巴开源 Open Code Review:确定性工程×Agent 混合架构的 AI 代码审查工具
阿里巴巴开源内部用两年的 AI 代码审查 CLI 工具 Open Code Review。采用确定性工程×Agent 混合架构,解决通用 Agent 审查的覆盖率不足和位置漂移问题。已在内部发现数百万代码缺陷。
2026年6月5日 · 阅读约 6 分钟
核心结论
阿里巴巴集团近日开源了其内部使用两年的 AI 代码审查 CLI 工具 Open Code Review(简称 OCR),该工具已在内部服务数万开发者、发现数百万代码缺陷。与市面主流 AI 代码审查方案不同,OCR 采用 确定性工程×Agent 混合架构 — 文件选择、分组、规则匹配等关键步骤由工程逻辑保证准确性,AI Agent 专注动态决策和上下文检索。简单配置一个模型端点即可开始使用。
关键要点
- 事件发生时间:2026-06-05(HN 首页热榜)
- 影响对象:使用 AI 辅助代码审查的开发团队
- 核心变化:阿里巴巴将内部大规模验证的 AI 代码审查工具开源,采用确定性约束 + Agent 混合架构,试图解决纯语言驱动方案的覆盖率漂移、位置偏移等问题
背景与触发事件
Open Code Review 起源于阿里巴巴集团的内部 AI 代码审查助手,经过两年大规模验证后以开源形式向社区发布。6 月 5 日登上 Hacker News 首页,获得 206 分和 60 条评论。
项目以 NPM 包 @alibaba-group/open-code-review 发布,安装后通过 ocr 命令使用。支持 GitHub Actions 集成、Claude Code 插件、独立 CLI 等多种使用方式。
OCR 的核心差距分析:通用 Agent 的三个痛点
Open Code Review 的 README 一开始就开诚布公地列出了通用 Agent 做代码审查的三个硬伤:
| 痛点 | 表现 | 根因 |
|---|---|---|
| 覆盖率不足 | 面对大变更集,Agent "偷工减料",只审部分文件 | 纯语言架构缺少对审查过程的硬约束 |
| 位置漂移 | 审查意见与实际代码位置不匹配 | LLM 对代码行号的感知不精确 |
| 质量不稳定 | 微调 prompt 就导致审查质量剧烈波动 | 自然语言驱动的 Skill 难以调试和固化 |
这三个痛点——如果你用 Claude Code 或 Codex 做过代码审查——应该一点都不陌生。
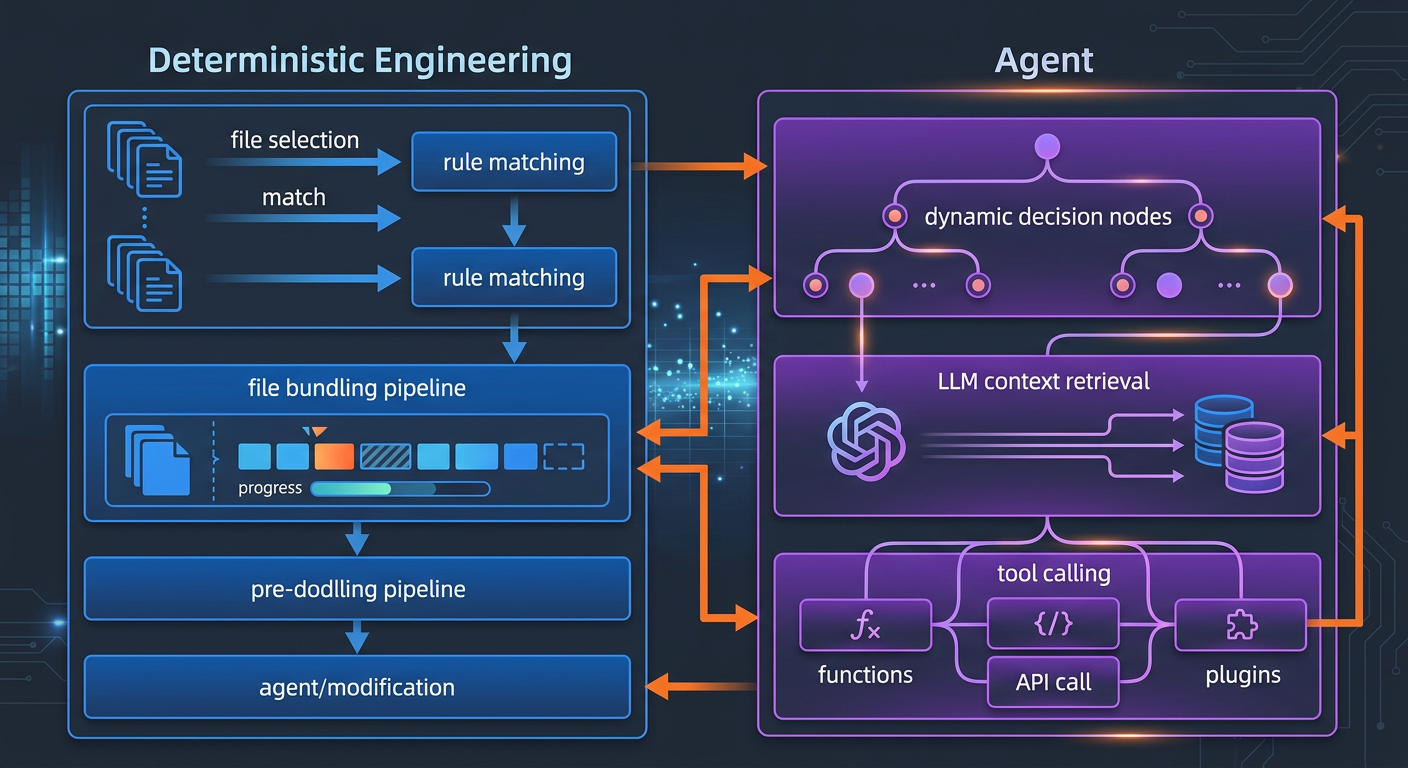
核心设计:确定性工程 × Agent 混合架构
OCR 的核心哲学是将确定性工程和 Agent 的优势分离开来,各管各的。
确定性工程 — 硬约束
对于"绝对不能出错"的步骤,用工程逻辑而非语言模型保障:
- 精确文件选择:确定哪些文件需要审查、哪些应该过滤,确保重要变更不被遗漏
- 智能文件打包:将相关文件合并为一个审查单元(如
message_en.properties和message_zh.properties一起审),每个包作为独立子 Agent 运行 - 精细化规则匹配:根据文件特性匹配审查规则,让模型注意力高度聚焦,信息噪声从源头消除
- 外部定位与纠偏模块:独立的评论定位和评论修正模块,系统性地提升 AI 反馈的位置准确性和内容准确性
Agent — 动态决策
Agent 的精力集中在它最擅长的地方:
- 场景调优的 prompt 模板:针对代码审查深度优化的 prompt,提升效果同时减少 token 消耗
- 场景调优的工具集:基于大规模生产数据中的工具调用轨迹分析(调用频率分布、单工具重复率、新工具对调用链的影响),提炼出专为代码审查定制的工具集
预置规则引擎
OCR 附带 15 种语言的审查规则,覆盖 Java、TypeScript/JavaScript、Python(default 规则)、C/C++、Kotlin、ArkTS 以及 JSON、YAML、Properties 等配置文件格式。规则文件目前为中文编写,社区已有志愿者完成英文翻译。
社区反应与行业解读
HN 社区对 OCR 的反响积极,但讨论主要集中在两个方向:
基准测试:74% 召回 vs 12% 精确
用户 eranation 在 Martian Code Review Benchmark(50 个 PR)上测试了 OCR 的 10 个 PR 子集:
- 召回率 ~74%:找到了大部分 golden issues,表现不错
- 精确率 ~12%:误报率较高,F1 约 20%
这引发了"召回优先还是精确优先"的经典讨论:
"发现问题是在为客户优化。减少误报是在为开发者优化。哪个对取决于你组织的文化。" — onion2k
"这与安全工具 90% 误报率时没人看警告是一样的。开发者会学会忽略它。" — chaoz_
竞争格局:生态位正在成型
社区提到的现有竞品包括:
- CodeRabbit:$30/月/开发者,被认为"能发现真正逻辑 bug",但有过安全漏洞历史(从 PR 到 RCE)
- Cursor BugBot:曾以 $40 固定价格受欢迎,已转为按次计费
- 自定义 Skill 方案:多名用户用 Claude Code 构建了自己的审查工具链
一位用户分享了他的多模型审查经验:
"我用 Opus 写代码,GPT-5.5 做同行审查,通过自动化 Skill 跑。不同模型的训练集不同,一个模型的盲点可能被另一个覆盖。" — cheema33
使用方式
OCR 提供多种集成方式:
独立 CLI
npm install -g @alibaba-group/open-code-review
# 配置 LLM
ocr config set llm.url https://api.anthropic.com/v1/messages
ocr config set llm.model claude-opus-4-6
# 审查工作区变更
ocr review
# 审查分支差异
ocr review --from main --to feature-branch与 Claude Code 集成
作为 Claude Code Plugin 安装:
/plugin marketplace add alibaba/open-code-review
/plugin install open-code-review@open-code-review然后通过 /open-code-review:review 斜杠命令使用。也可直接复制命令文件到 .claude/commands/ 目录。
作为 AI 编码 Agent 的 Skill
npx skills add alibaba/open-code-review --skill open-code-review安装后,Agent 可自动在代码审查时调用 ocr 命令。

适配建议
- 中小团队:直接安装 CLI 配合 Claude Code 使用,零成本起步
- 审查流程自动化:配置 GitHub Actions 或 webhook 自动触发审查
- 规则定制:基于预置 15 种语言规则自定义,适配团队编码规范
- 注意误报率:12% 精确率意味着大量误报需要人工筛选——建议将 OCR 作为补充审查而非替代人工
- 多模型策略:用不同模型审查同一次变更,交叉验证可有效降低误判概率
工具词条
正文中自然出现的工具:OpenAI、Claude、Claude Code、Codex、Cursor、Gemini、GitHub
内链引导
- 想学 AI 安全审查?看:Anthropic 开源漏洞发现框架教程
- 想学 AI 编程 Agent 安全配置?看:AI 编程 Agent 安全配置教程
- 如何选择 AI 编程工具?看:AI 编程 Agent 选型指南